15 Haziran 2026 · Haberler
Splunk ITSI & AIOps: Bir Solution Brief'in Sahadaki Karşılığı
Son dönemde Türkiye Splunk ekosisteminde dolaşan güzel bir Splunk ITSI & AIOps solution brief'i var; Splunk Staff Solutions Engineer Ali Çetin tarafından hazırlandı. ITSI'ı monitoring çözümlerinin üzerinde bir "çatı katman" (umbrella layer) olarak konumlandırıyor; silolaşmış telemetri ekosisteminin üç temel sorununu adlandırıyor ve Observe → Engage → Analyze → Act → Learn döngüsüyle AIOps'un nasıl çalıştığını anlatıyor.
Bu yazı, o anlatının sahadaki karşılığı. Çünkü brief'in çerçevelediği üç sorunu ve o döngüyü, 2023'de bir kamu kurumunda yürüttüğümüz gerçek bir ITSI POC'unda birebir yaşadık. Kısa versiyonu şu: altyapı zaten oradaysa, görünürlük sandığınızdan çok daha yakın.
Brief'in adreslediği üç sorun, sahadaki üç sıkıntı
Solution brief, silolaşmış bir telemetri yapısının üç sorununu sayıyor. POC'ye başladığımızda müşterinin tablosu tam olarak bu üçünün canlı haliydi:
- Data Silo
- Her araç kendi verisini izole üretip saklıyordu; sistemin bütününe dair ortak bir görünürlük yoktu. Müşteride Splunk Enterprise ve Enterprise Security vardı, log'lar akıyordu — ama servis seviyesinde tek bir sağlık göstergesi yoktu. Veri vardı, görünürlük yoktu.
- Lack of Correlation
- Bir servis yavaşladığında, sorunun kaynağını (altyapı mı, ağ mı, bir bağımlılık mı) anlamak için ekip manuel ve uzun araştırmalar yapıyordu. Yük arttıkça servislerde yavaşlama ve kesintiler oluyor, her olayda kök neden analizi saatler alıyordu.
- Alarm Fatigue
- Aynı kök nedene bağlı onlarca uyarı, ekibin "gerçek sorunu" ayırt etmesini zorlaştırıyordu.
Yani brief'in soyut çerçevesi, sahada gayet somut görülüyordu.
Çözüm: sıfırdan değil, mevcut yatırımın üzerine
Müşterinin elinde zaten Splunk Enterprise ve Enterprise Security vardı. Altyapı mevcuttu; eksik olan operasyonel görünürlük katmanıydı. DataVira olarak mevcut yatırımın üzerine bir ITSI POC konumlandırdık.
Brief'in "Any Data, Any Source" ve "merkezileştirilmiş metric / log / iz" vurgusu, teknik bir gerçeğe dönüşüyordu. Aşağıdaki mimari, "mevcut yapı" ile "POC kapsamında eklenenleri" gösteriyor:
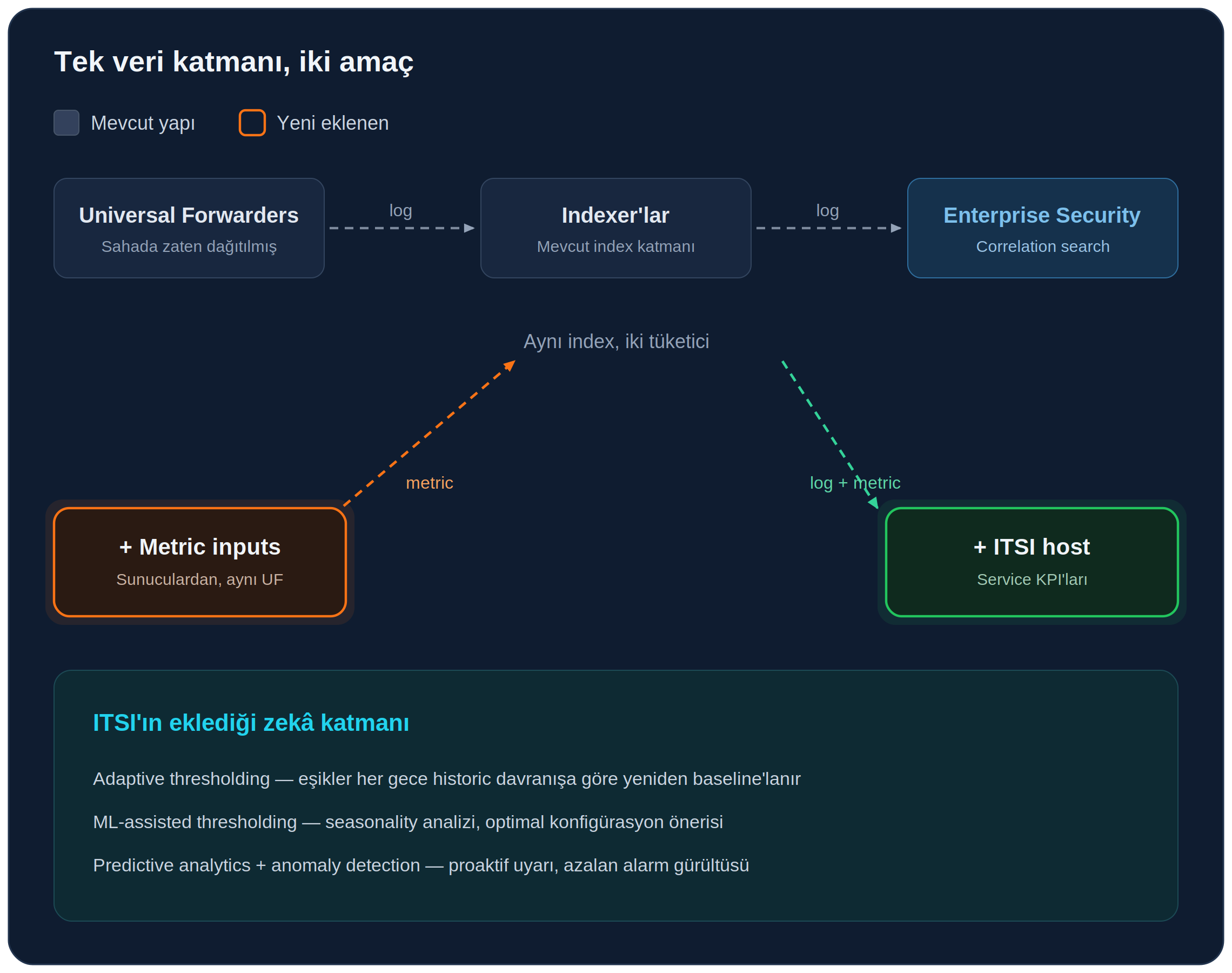
Bu diyagramın anlattığı kritik nokta şu: sıfır ek collection katmanı.
- Sahadaki Universal Forwarder'lar zaten dağıtılmıştı, log'lar zaten indexer'lara gidiyordu
- SIEM amacıyla toplanan bu veriye, yeni bir agent kurmadan, aynı UF altyapısı üzerinden sunuculardan metric input'ları eklendi.
- Aynı raw event hem Enterprise Security tarafında bir correlation search'ü besliyor, hem ITSI tarafında bir service KPI'ına dönüşüyor.
Ayrı bir monitoring stack'inde olsa, aynı veriyi ikinci kez toplamak, ayrı agent'lar yönetmek ve iki farklı data pipeline'ını senkron tutmak gerekirdi. Splunk üzerinde ise tek index katmanı iki tüketiciye birden hizmet ediyor.
POC kapsamında tek bir service'i, üstelik kısmen implement ettik. KPI base search'ler mevcut index'ler üzerinden tanımlandığı için entity discovery ve service kurulumu hızlı ilerledi. Bu dar kapsamda bile daha önce fark edilmemiş birkaç problem tespit edilip çözüldü. DevOps ve sistem operasyon ekibinin ürünü benimsemesi tam bu aşamada oldu.
Brief'in döngüsü POC'de nasıl işledi: Observe → Engage → Analyze → Act → Learn
Solution brief, AIOps'u beş aşamalı bir döngüyle anlatıyor. POC'miz dar kapsamlıydı ama bu döngünün her aşamasının nasıl somutlaştığını net gösterdi:
- Observe
- Servis ağları üzerinden metric, log ve iz verilerinin merkezileştirilmesi. Bizde bu, mevcut UF altyapısına metric input'larının eklenmesiyle, sıfır ek collection ile gerçekleşti.
- Engage
- Davranışsal sapmalar için ML tabanlı baseline öğrenimi. ITSI'ın adaptive thresholding'i, historic KPI davranışını her gece yeniden baselineları güncelleyip eşikleri saat saat değişen yüke göre ayarladı. Gece doğal olarak düşen trafiğin ürettiği yanlış alarmlar büyük ölçüde ortadan kalktı. Detay: Create adaptive KPI thresholds in ITSI.
- Analyze
- Event IQ ile akıllı gruplandırma ve gürültü azaltma; anomaly detection ile normal dışı sapmaların yakalanması. Bu, brief'in "Alarm Fatigue" sorununa doğrudan yanıt: alarm gürültüsü kesilince ekip asıl business impact'e odaklanabildi.
- Act
- Otomatik runbook ve ITSM entegrasyonlarıyla kendi kendini iyileştirme yönü. Bizim POC kapsamımızda bu aşamayı tam devreye almadık, ama mimarinin buna açık olduğunu gösterdik.
- Learn
- Operatör geri bildirim döngüleriyle sürekli iyileştirme. Adaptive baseline'ların her gece yeniden hesaplanması, sistemin zamanla daha isabetli hale gelmesini sağladı.
ITSI'ın asıl değeri: dashboard'larda değil, ML katmanında
ITSI'ın görünen yüzü Service Analyzer'dır — servislerin 0-100 arası health score'larını renk-kodlu tile'larla gösteren ekran. Splunk'ın resmî dokümanında bu görünümü inceleyebilirsiniz: Overview of the Service Analyzer in ITSI.
Ama POC'den bana kalan asıl ders, brief'in de vurguladığı gibi, ITSI'ın değerinin bu görsel katmanda değil, altındaki makine öğrenmesi katmanında olduğuydu.
ML-assisted thresholding
Adaptive thresholding eşikleri otomatik ayarlar; bir adım ötesi, eşik konfigürasyonunu da makineye bırakmaktır. ML-assisted thresholding, verideki seasonality ve pattern'leri analiz ederek her KPI için optimal threshold konfigürasyonunu önerir. Eskiden bir KPI'ı manuel tune etmek görsel analiz ve tahmin gerektiren yarım günlük bir işti; bu özellikle saniyelere iniyor. Öneriyi olduğu gibi uygulayabilir ya da kendiniz ince ayar yapabilirsiniz — esneklik kaybolmuyor. Splunk dokümanı: Configure KPI thresholds with machine learning in ITSI.
Predictive analytics
ITSI'ın AI tarafının en vurucu yeteneği bu: geçmiş service health score'larını ve trend/pattern'leri analiz ederek olası service degradation'larını önceden öngörmek. Splunk'ın kendi ifadesiyle, predictive analytics incidentleri makine öğrenmesi algoritmalarıyla 30 dakika öncesinden tahmin edebilir. Bu, operasyonu reaktiflikten çıkarıp proaktif hale getirir — bir CPU spike'ı servise yansımadan önce kaynak ölçeklemek gibi. Splunk dokümanı: Overview of Predictive Analytics in ITSI.
Service Tree ve deep dive
Brief'in "Service Tree topolojisi" dediği şey, kök neden analizinde belirleyici. Alt bileşenlerdeki bir sorun üst hizmetin sağlık skoruna anında yansır; böylece uygulamadan altyapıya kadar kök neden saniyeler içinde daralır. Kök neden analizini derinleştirmek için ise deep dive'lar, çoklu KPI'ı swim lane görünümünde yan yana getirip zaman içinde korele etmenizi sağlar — MTTR'yi doğrudan düşüren araç budur. Splunk dokümanı: Overview of deep dives in ITSI.
Sonuç: brief teoriyi kurdu, saha kanıtladı
POC'nin çıktısı netti: ITSI kullanılarak service quality yükseldi, MTTR belirgin şekilde düştü. Ama daha önemlisi, müşteri zaten Splunk'a SIEM olarak yatırım yapmış olduğu için, ITSI eklemek sıfırdan ayrı bir AIOps ürünü edinmekten hem maliyet hem teknik açıdan çok daha verimli oldu.
Veri zaten oradaydı, forwarder'lar zaten yerindeydi, platform zaten hazırdı. Eklenen tek şey, o verinin üzerindeki operasyonel zekâ katmanıydı.
Solution brief'in anlattığı ITSI & AIOps anlatısı doğru ve güçlü. Bizim eklediğimiz tek şey, o anlatının sahada gerçekten işlediğine dair bir kanıt. Splunk'ı bir SIEM olarak çalıştırıyorsanız, ITSI'ı ayrı bir ürün değil, aynı yatırımın bir sonraki adımı olarak görmek mantıklı. Görünürlük, çoğu zaman bir POC kadar uzakta.
DataVira, Türkiye'nin Splunk-odaklı Elite Partner'ıdır. Splunk mimarisi, Enterprise Security ve ITSI üzerine sahadaki POC ve production deneyimlerimiz hakkında konuşmak isterseniz datavira.com üzerinden ulaşabilirsiniz.
Görseldeki ITSI ekran görünümleri için bağlantı verilen kaynaklar Splunk'ın resmî dokümantasyonuna aittir.
İletişim: [email protected]